I recently finally had occasion to learn some incredibly handy new command-line tricks I've been wanting to figure out for some time. Namely, controlling Directory Access parameters. I've long hoped for and wondered if there was a way to do this, and some of my more ingenious readers finally confirmed that there was, in the comments to a recent article. And now, with initiative and time, I've figured it all out and want to post it here for both your and my benefit, and for the ages (or at least until Apple decides to change it).
The occasion for learning all this was a wee little problem I had with my Mac OS X clients. For some reason, which I've yet to determine, a batch of them became hopelessly unbound from the Open Directory master on our network.

Weird Client Problem: "Some" Accounts Available? Huh?
(click image for larger view)
The solution for this was to trash their DirectoryService preferences folder, and then to rebind them to the server. This was always something I'd done exclusively from the GUI, so doing it on numerous clients has always been a pain: log into the client machine, trash the prefs, navigate to and open the Directory Access application, authenticate to the DA app, enter the OD server name, authenticate for directory binding, and finally log back out. Lather, rinse, repeat per client. Blech! The command-line approach offers numerous advantages, the most obvious being that this can all be scripted and sent to multiple machines via Apple Remote Desktop. No login required, no GUI needed, and you can do every machine at once.
The command-line tools for doing all this are not exactly the most straightforward set of commands I've ever seen. But they exist, and they work, and they're quite flexible once you parse them out. The first basic thing you need to understand is that there are two tools for accomplishing the above: dscl and dsconfigldap. The dsconfigldap command is used to add an LDAP server configuration to Directory Access. The dscl command adds that server to the Authentication and Contacts lists in Directory Access, and is used to configure the options for service access.
So typically, your first step in binding a client to an OD master in Directory Access is to add it to the list of LDAPv3 servers. This can be done via the command-line with dsconfigldap, like so:
sudo dsconfigldap -s -a systemsboy.com -n "systemsboy"
We like to use directory binding in our configuration, and this can be accomplished too:
sudo dsconfigldap -u diradmin -i -s -f -a systemsboy.com -c systemsboy -n "systemsboy"
The above command requires a directory administrator username and interactively requests a password for said user. But if you want to use ARD for all of this, you'll need to supply the password in the command itself:
sudo dsconfigldap -u diradmin -p 'DirectoryAdmin_Password' -s -f -a systemsboy.com -c systemsboy -n "systemsboy"

Directory Access: Adding an OD Server Configuration
(click image for larger view)
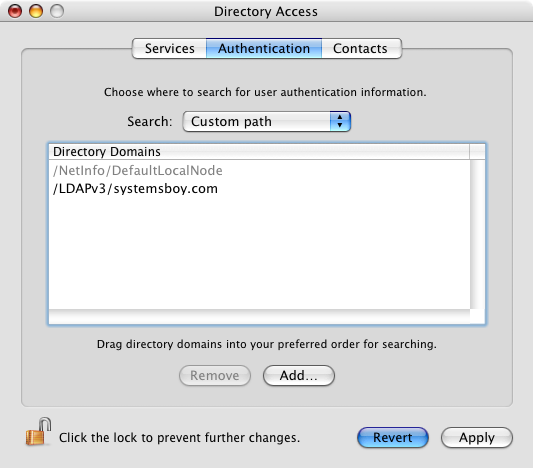
So, there you have it. You've now added your OD master to your list of LDAPv3 servers. You can see this reflected immediately in the Directory Access application. But, unlike in DA, the command does not automatically populate the Authentication and Contacts fields. Your client will not authenticate to the OD master until you have added the OD server as an authentication source. To do this you use dscl. You'll need a custom Search Path for this to work. You may already have one, but if you don't you can add one first:
dscl -q localhost -create /Search SearchPolicy dsAttrTypeStandard:CSPSearchPath
And now add the OD master to the Authentication search path you just created:
sudo dscl -q localhost -merge /Search CSPSearchPath /LDAPv3/systemsboy.com

Directory Access: Adding an OD Authentication Source
(click image for larger view)
If you want your OD server as a Contacts source as well, run:
sudo dscl -q localhost -merge /Contact CSPSearchPath /LDAPv3/systemsboy.com
Again, this change will be reflected immediately in the DA application. You may now want to restart Directory Services to make sure the changes get picked up, like so:
sudo killall DirectoryService
And that's really all there is to it. You should now be able to log on as a network user. To test, simply id a know network-only user:
/>If you get this error:
Something's wrong. Try again.
If all is well, though, you'll get the user information for that user:
uid=503(spaz) gid=503(spaz) groups=503(spaz)
You should be good to go.
And, if you want to view all this via the command-line as well, here are some commands to get you started.
To list the servers in the configuration:
dscl localhost -list /LDAPv3
To list Authentication sources:
dscl -q localhost -read /Search
To list Contacts sources:
dscl -q localhost -read /Contact
A few things before I wind up. First, some notes on the syntax of these commands. For a full list of options, you should most definitely turn to the man pages for any of these commands. But I wanted to briefly talk about the basic syntax, because to my eye it's a bit confusing. Let's pick apart this command, which adds the OD master to the configuration with directory binding and a supplied directory admin username and password:
sudo dsconfigldap -u diradmin -p 'DirectoryAdmin_Password' -s -f -a systemsboy.com -c systemsboy -n "systemsboy"
The command is being run as root (sudo) and is called dsconfigldap. The -u option tells the command that we'll be supplying the name of the directory admin to be used for binding to the OD master (required for such binding). Next we supply that name, in this case diradmin. The -p option allows you to specify the password for that user, which you do next in single quotes. The -s option will set up secure authentication between server and client, which is the default in DA. The -f option turns on ("forces") directory binding. The -a option specifies that you are adding the server (as opposed to removing it). The next entry is the name of the OD server (you can use the Fully Qualified Domain Name or the IP address here, but I prefer FQDN). The -c option specifies the computer ID or name to be used for directory binding to the server, and this will add the computer to the server's Computers list. And finally, the -n option allows you to specify the configuration name in the list of servers in DA.
Now let's look at this particular use of dscl:
sudo dscl -q localhost -merge /Search CSPSearchPath /LDAPv3/systemsboy.com
Again, dscl is the command and it's being run as root. The -q option runs the command in quiet mode, with no interactive prompt. (The dscl command can also be run interactively.) The localhost field specifies the client machine to run the command on, in this case, the machine I'm on right now. The -merge flag tells dscl that we want to add this data without affecting any of the other entries in the path. The /Search string specifies the path to the Directory Service datasource to operate on, in this case the "Search" path, and the CSPSearchPath is our custom search path key to which we want to add our OD server, which is named in the last string in the command.
Whew! It's a lot, I know. But the beauty is that dscl and dsconfigldap are extremely flexible and powerful tools that allow you to manipulate every parameter in the Directory Access application. Wonderful!
Next, to be thorough, I thought I'd provide the commands to reverse all this — to remove the OD master from DA entirely. So, working backwards, to remove the server from the list of Authentication sources, run:
sudo dscl -q localhost -delete /Search CSPSearchPath /LDAPv3/systemsboy.com
To remove it from the from the Contacts source list:
sudo dscl -q localhost -delete /Contact CSPSearchPath /LDAPv3/systemsboy.com
And to remove a directory-bound configuration non-interactively (i.e. supplying the directory admin name and password):
sudo dsconfigldap -u diradmin -p 'DirectoryAdmin_Password' -s -f -r systemsboy.com -c systemsboy -n "systemsboy"
If that's your only server, you should be back to spec. Just to be safe, restart DirectoryService again:
sudo killall DirectoryService
If you have a bunch of servers in your Directory Access list, you could script a method for removing them all with the above commands, but it's probably easier to just trash the DirectoryService prefs (in /Library/Preferences) and restart DirectoryService.
Lastly, I'd like to end this article with thanks. Learning all this was kind of tricky for me, and I had a lot of help from a few sources. Faithful readers MatX and Nigel (of mind the expla
natory gap fame) both pointed out the availability of all this command-line goodness. And nigel got me started down the road to understanding it all. Most of the information in this article was also directly gleaned from another site hosted in my home state of Ohio, on a page written by a Jeff McCune. With the exception of a minor tweak here and there (particularly when adding Contacts sources), Jeff's instructions were my key to truly understanding all this, and I must thank him profusely. He made the learning curve on all this tolerable.
So thanks guys! It's help like this that makes having this site so damn useful sometimes, and it's much appreciated.
And now I'm off to go bind some clients command-line style!
UPDATE:
Got to test all this out real-world style today. Our server got hung up again, and we had the same problem I described at the head of this article. No one could log in. So I started trying to use the command-line to reset the machines. I had one major snag that caused it all to fail until I figured out what was going on. Seems I could not bind my machines to the server using the -s flag (secure binding). I had thought that this was the default, and that I was using it before, but now I'm not so sure. In any case, if you're having trouble binding or unbinding clients to a server, try the dsconfigldap command without the -s flag if you can, like so:
sudo dsconfigldap -u diradmin -p 'DirectoryAdmin_Password' -f -a systemsboy.com -c systemsboy -n "systemsboy"
That's what worked for me. I'm a little concerned that this is indicative of a problem on my server, but now's not really the time to go screwing with stuff, so I'll leave it alone for the time being.
This update brought to you by the little letter -s.